Storm Spout
通过实现Storm中的ISpout接口,重写其中的nextTuple、ack和fail方法,可以实现tuple流的发送、成功确认、失败重发。ISpout接口代码如下所示。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32public interface ISpout extends Serializable {
/**
* work进程初始化spout时运行该方法
*/
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
/**
* 关闭时调用,但不保证一定调用(kill -9)
*/
void close();
/**
* activate topology后调用
*/
void activate();
/**
* deactivate topology后调用
*/
void deactivate();
/**
* 在nextTuple中通过调用collector的emit方法发送tuple
* nextTuple、ack和fail这三个方法在一个线程中被循环调用
*/
void nextTuple();
/**
* msgId标识的消息处理成功后调用该方法
*/
void ack(Object msgId);
/**
* msgId标识的消息处理失败后调用该方法
* 可以进行消息的重新发送
*/
void fail(Object msgId);
}
storm-kafka
storm-kafka模块目前集成中在storm中,为storm提供读取kafka消息队列的支持,其中,KafkaSpout类继承自BaseRichSpout类,用于从kafka消息队列中读取消息发送tuple,对tuple进行成功确认和失败重发,保证kafka消息至少被处理一次。
KafkaSpout
KafkaSpout类核心逻辑的序列图如下所示。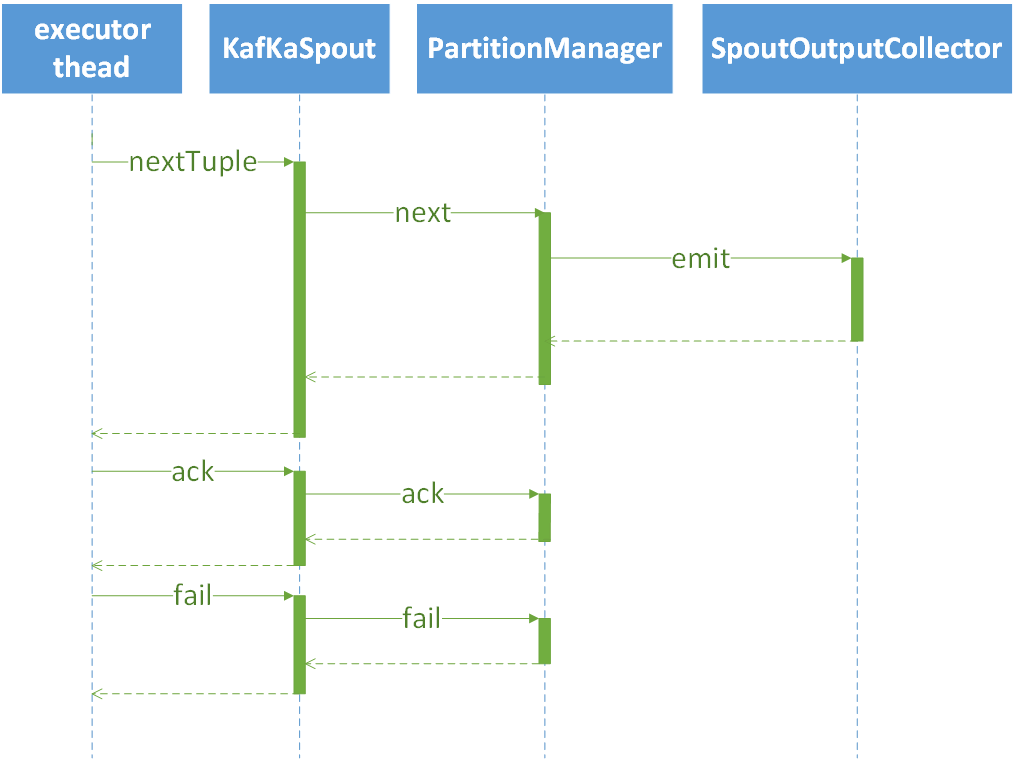
从中可以看出,发送tuple,成功确认和失败重发都是由PartitionManager这个类完成。
在storm中,可以设置spout的并行度,也就是说可以有多个KafkaSpout实例从一个kafka队列中读取消息,而kafka作为大数据应用场景下的消息队列,其每个队列可以配置为多个partition,每个partition可以由一个消费者读取消息,这样可以保证消息消费的大吞吐量。当在storm集群中使用KafkaSpout类读取消息时,需要控制每个KafkaSpout实例读取kafka队列的哪几个partition,如果实例数等于partition数,那么每个KafkaSpout实例从一个partiton中读取消息。
在KafkaSpout类中有一个成员变量PartitionCoordinator _coordinator,_coordinator中有一个成员变量Map\<Partition, PartitionManager> _managers。通过在zookeeper上保存信息,_coordinator可以在storm集群中协调各个KafkaSpout实例读取哪几个partition,并通过_managers管理当前所在KafkaSpout实例负责的partition的读取,而PartitionManager类则具体负责某个partition的读取。
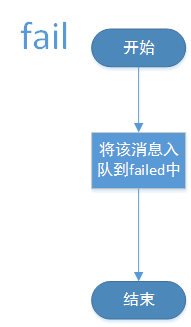
当KafkaSpout实例执行nextTuple方法时,会从_coordinator中获取到PartitonManager实例,并调用该实例的next方法,而当KafkaSpout实例执行ack方法时,实际调用了PartitonManager的ack方法,而当KafkaSpout实例执行fail方法时,实际调用了PartitonManager的fail方法。PartitionManager的next、ack和fail方法具体流程如下所示。
next

ack

fail