Flume是一个分布式、高可用日志收集系统,可以收集不同来源的日志并集中存储。目前Flume是Apache顶级项目。
架构
数据流模型
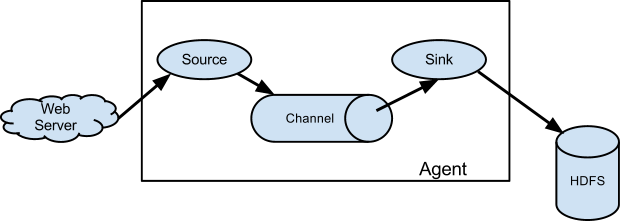
Flume Agent是一个JVM进程,包含三个基本组件:
- Source,用于从外部数据源获取数据;
- Channel,用于暂存数据;
- Sink,用于向目标发送数据。
Source
Flume支持以下Source:
- Avro Source,侦听Avro端口,接收外部Avro客户端发送的数据;
- Thrift Source,侦听Thrift端口,接收外部Thrift客户端发送的数据;
- Exec Source,执行Unix命令,并将标准输出作为外部数据源,例如,可以使用“cat [named pipe]”或“tail -F [file]”命令持续地输出数据作为外部数据源;
- JMS Source,从JMS消息队列或主题中读取消息作为外部数据源;
- Spooling Directory Source,将目录下的文件作为外部数据源,当有新文件加入目录时,则读取文件中的数据;
- Kafka Source,从Kafka topic中读取消息作为外部数据源;
- NetCat Source,侦听某个端口,按行接收数据作为外部数据源;
- Sequence Generator Source,产生从0开始,按1递增的序列作为外部数据源,主要用于测试;
- Syslog Sources,读取syslog作为外部数据源;
- HTTP Source,将HTTP GET和POST请求作为外部数据源;
- Stress Source,内部产生数据用于压力测试;
- Legacy Sources,接收Flume 0.9.4发送的数据并作适配,作为Flume 1.x的外部数据源;
- Scribe Source,适配Scribe,将Scribe作为外部数据源。
Channel
Flume支持以下Channel:
- Memory Channel,将数据暂存在内存队列中;
- JDBC Channel,将数据暂存在数据库中;
- Kafka Channel,将数据暂存在Kafka集群中;
- File Channel,将数据暂存在文件中;
- Spillable Memory Channel,同时使用内存和文件暂存数据。
Skin
Flume支持以下Sink:
- HDFS Sink,将数据发送至HDFS;
- Hive Sink,将数据发送至Hive;
- Logger Sink,以日志方式输出数据,主要用于测试;
- Avro Sink,以Avro方式将数据发送到其他的Avro服务器端;
- Thrift Sink,以Thrift方式将数据发送到其他的Thrift服务器端;
- File Roll Sink,将数据发送至本地文件;
- Null Sink,不再发送数据;
- HBaseSinks,将数据发送至HBase;
- MorphlineSolrSink,将数据发送至Solr;
- ElasticSearchSink,将数据发送至ElasticSearch;
- Kafka Sink,将数据发送至Kafka Topic。
安装
直接下载和解压可执行包:
tar -zxvf apache-flume-1.5.0.1-bin.tar.gz
ln -s apache-flume-1.5.0.1-bin flume
配置
以tail -F方式读取nginx日志,使用内存暂存并发送到Kafka topic,配置mp_pv_producer.properties如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29#agent section
mp_pv_producer.sources=s
mp_pv_producer.channels=c
mp_pv_producer.sinks=r
#source section
mp_pv_producer.sources.s.type=exec
mp_pv_producer.sources.s.channels=c
mp_pv_producer.sources.s.restart=true
mp_pv_producer.sources.s.restartThrottle=500
mp_pv_producer.sources.s.command=tail -f /data/logs/nginx/access.log
# Each sink's type must be defined
mp_pv_producer.sinks.r.type=org.apache.flume.plugins.KafkaSink
mp_pv_producer.sinks.r.metadata.broker.list=10.16.3.97:9092,10.16.3.172:9092
mp_pv_producer.sinks.r.partition.key=0
mp_pv_producer.sinks.r.partitioner.class=org.apache.flume.plugins.SinglePartition
mp_pv_producer.sinks.r.serializer.class=kafka.serializer.StringEncoder
mp_pv_producer.sinks.r.request.required.acks=0
mp_pv_producer.sinks.r.max.message.size=1000000
mp_pv_producer.sinks.r.producer.type=sync
mp_pv_producer.sinks.r.custom.encoding=UTF-8
mp_pv_producer.sinks.r.custom.topic.name=mp_pv
#Specify the channel the sink should use
mp_pv_producer.sinks.r.channel=c
# Each channel's type is defined.
mp_pv_producer.channels.c.type=memory
mp_pv_producer.channels.c.capacity=1000
启动
nohup bin/flume-ng agent –conf conf –conf-file conf/mp_pv_producer.properties –name mp_pv_producer -Dflume.root.logger=INFO,console &